UseScraper - Fast, efficient, unlimited web scraping
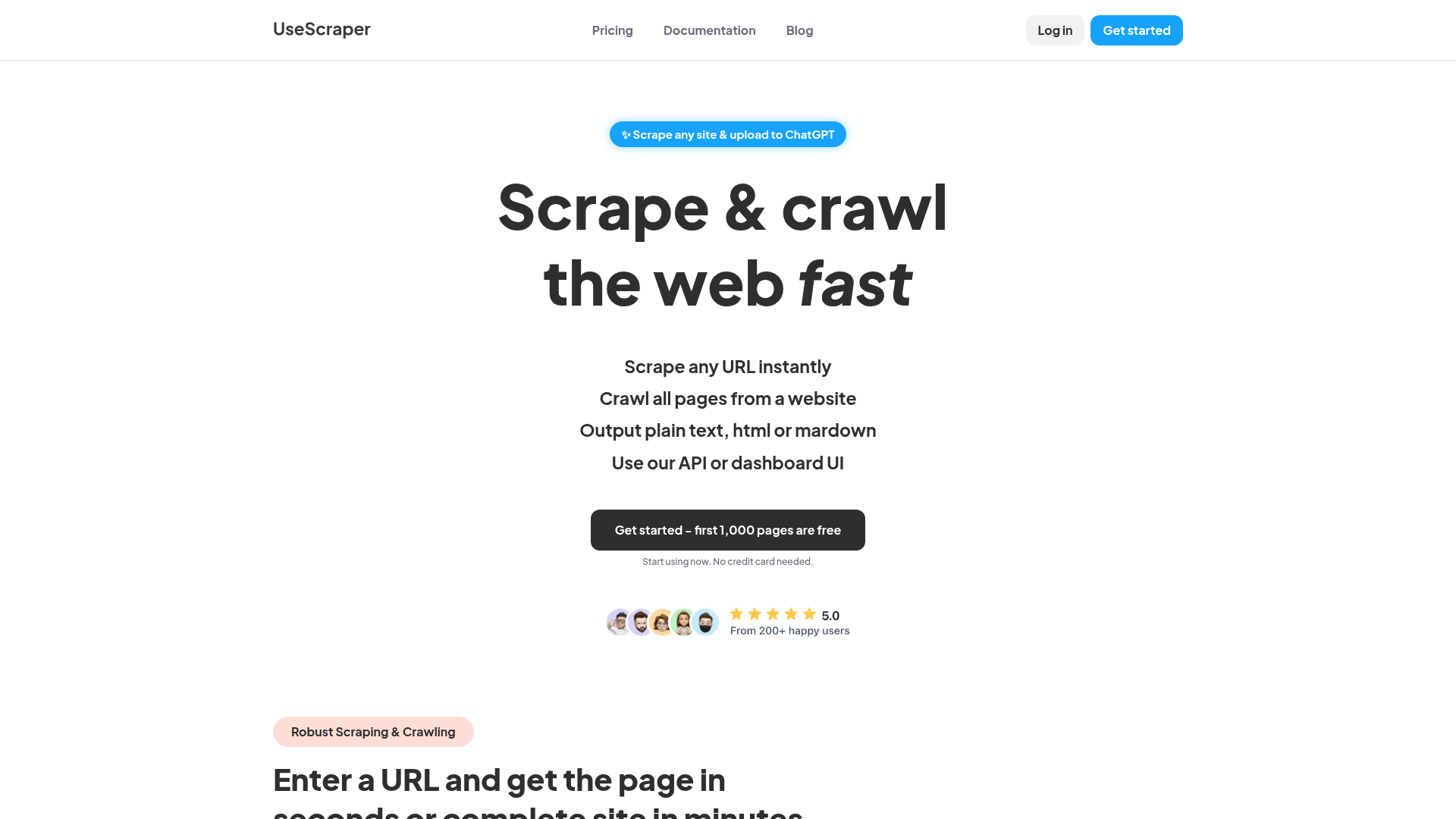
To fully understand how UseScraper operates, let's break down its core functionalities and features:
- Url-Based Scraping: Users input a URL, and the scraper quickly retrieves the page content. This allows for immediate access to needed information.
- Crawling Sites: For comprehensive data needs, the crawler can fetch sitemaps and rapidly iterate through numerous pages, upwards of thousands per minute, giving you bulk data quickly.
- JavaScript Rendering: Utilizing a real Chrome browser, complex web pages loaded with JavaScript are rendered fully, ensuring accurate data extraction from dynamic sites.
- Output Flexibility: Users can choose their desired output format—be it HTML, plain text, or the AI-friendly Markdown format—allowing for versatile application of the data.
- Automatic Proxy Use: To mitigate scraping blocks, the system employs auto rotating proxies, ensuring consistent access to sites without interruption from rate limiting or bans.
- Customizable Crawl Features: Users can include numerous sites in one job, exclude specific content using CSS selectors, and receive notifications on job statuses via webhooks, enhancing control over the scraping process.
Getting started with UseScraper is a breeze. Follow these simple steps:
- Sign Up: Create your free account on our platform to access our resources.
- Choose Your Plan: Review our flexible pricing options, including a free plan with $25 in credits to test our services.
- Enter URL for Scraping: Input the desired website URL into the tool. If you're looking to scrape multiple pages, you can also upload a sitemap directly.
- Configure Settings: Tailor your scraping job based on your needs—set data formats, specify any exclusion patterns, and configure proxies to avoid rate limits.
- Start the Job: Once you're satisfied with your configurations, initiate the scraping task and monitor the progress through real-time notifications.
- Access Your Data: When completed, access your results securely stored in our data store via the API for immediate use in your applications.
In an era where data is king, UseScraper equips you with the necessary tools to harness information efficiently and effectively. With a commitment to speed, accuracy, and adaptability, our powerful web scraping solution is designed to meet diverse data needs regardless of complexity. Sign up today and capitalize on our dedicated features to propel your projects forward, unlocking the potential of web data for your business or research. Begin your journey now and enjoy a $25 credit to experience our robust capabilities firsthand.
Features
Rapid Page Retrieval
Enter a URL and receive content within seconds.
Bulk Data Crawling
Fetch entire site data quickly with scalable infrastructure.
JavaScript Rendering
Accurately scrape dynamic and complex web pages.
Markdown Output
Perfect Markdown conversion for AI applications.
Rotating Proxies
Auto rotating proxies to bypass scraping restrictions.
Custom Notifications
Receive webhook notifications on crawl job status.
Use Cases
E-commerce Data Collection
Scrape product details and prices from competitor websites for market analysis.
Academic Research
Extract relevant data from academic journals and websites for analysis.
Content Aggregation
Collect diverse content for blogs or newsletters from multiple sources.
Social Media Monitoring
Monitor brand mentions by scraping social media pages.
Travel Price Comparison
Gather travel deal information from various booking sites.
Real Estate Listings
Compile real estate listings for trends and market insights.
FAQs
Traffic(2025-03)
Monthly Traffic
Traffic Source
Top Keywords
| Keyword | Traffic | Volume | CPC |
|---|---|---|---|
| pay per use web crawler | 97 | 20 | - |
| website crawler api | 87 | 100 | - |
| web scraper api | 53 | 1540 | 4.54 |
| fastest web crawl api | 38 | 10 | - |
| api crawler online | 35 | 20 | - |
Source Region
Whois
| Domain | usescraper.com |
| Creation Date | 2025-08-15 13:24:40 |
| Last Updated | 2024-07-16 04:02:18 |
| Domain Status | clienttransferprohibited, //icann.org/epp |
| Registrar | Cloudflare, Inc. |
| Registrar IANA ID | 1910 |
| Registrar URL | http://www.cloudflare.com |
Featured Products
Atlas
Bolt.New
LastMileAI
Napkin
Glide
Rosebud
Appen
FlutterFlow
Related Categories
Copy embed code
Alternative Products

Helpedby AI

Outerspan
Blnk Finance

Okareo

HostedMCPPlatform

BackflipAI


AiNativeDeveloperToolsLandscape