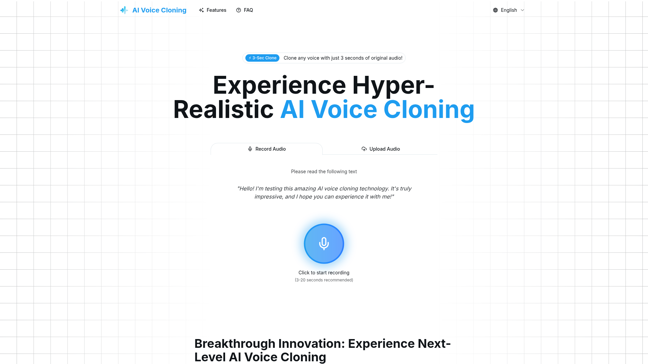
Voila - Real-time expressive voice AI

"Imagine having a conversation with an AI that doesn't just respond—it anticipates, emotes, and keeps pace with human spontaneity. That's the promise of Voila, and it's rewriting the rules of voice interaction."
Breaking the Voice AI Bottleneck
Traditional voice assistants frustrate us with:
- 🐢 Laggy responses (ever counted Mississippi's waiting for Alexa?)
- 🤖 Robotic tones that make Siri sound like she's reading a teleprompter
- � Disjointed interactions where context disappears between queries
Voila smashes these limitations with:
- ⚡ 195ms response latency (faster than human reaction time)
- 🎭 Emotional resonance through nuanced vocal delivery
- 🔄 Full-duplex conversations where interruptions feel natural
How Voila Works: Technical Magic Made Simple
At its core, Voila combines three breakthrough innovations:
-
Hierarchical Multi-Scale Transformer Architecture
- Think of it as an orchestra conductor coordinating LLM reasoning with acoustic precision
- Processes audio at different time resolutions for both immediate response and long-term coherence
-
Persona-Aligned Voice Synthesis
- From Homer Simpson to Elon Musk with text instructions alone
- Over 1M pre-built voices + custom voices from 10-second samples
-
Unified Multitask Framework
- ASR, TTS, and speech translation in one model
- Adapts to new languages with minimal training
Real-World Applications That Don't Feel Like Sci-Fi
🎤 Dynamic Voice Role-Play
Watch historical figures debate or have your favorite TV characters argue about coffee vs. tea. The demo where Homer Simpson discusses junk food avoidance shows emotional range I've never heard in synthetic voices.
🌍 Multilingual Business Tools
Global teams could use Voila for:
- Real-time meeting transcription with speaker identification
- Emotion-preserving translation during negotiations
- Brand-consistent voiceovers across markets
🧠 Next-Gen Accessibility
For users with visual impairments, Voila's proactive interaction style could revolutionize device navigation—anticipating needs before explicit commands.
Why This Matters for Developers & Businesses
The open-source nature (available on Hugging Face) means:
-
No Vendor Lock-In
Unlike proprietary solutions from Big Tech, Voila's architecture can be customized for niche use cases -
Cost-Effective Scaling
Single-model efficiency reduces computational overhead compared to patched-together solutions -
Future-Proof Foundation
The unified framework readily incorporates advances in both language and acoustic modeling
The Road Ahead: Challenges & Opportunities
While testing the web demo, I noticed two areas for growth:
-
Emotional Consistency
While tones are expressive, sustaining character-appropriate affect over long dialogues needs refinement -
Background Noise Handling
The model excels in clean audio environments but shares the field's struggle with chaotic real-world settings
Yet these are solvable problems—the architecture is designed for continuous learning. As the team notes in their GitHub repo, this is just the starting point for "AI-powered realities."
Your Move in the Voice AI Revolution
For developers:
🔧 Fork the repo and experiment with persona blending—what happens when you merge Shakespeare with Cardi B's vocal patterns?
For product teams:
📞 Prototype customer service flows where the agent adjusts tone based on sentiment detection
For everyday users:
🎤 Try the demo and experience how debate partners can dynamically interrupt each other—no awkward pauses
The era of transactional voice commands is ending. With Voila, we're entering the age of conversational partnership with machines that don't just listen—they understand.
Features
Real-time interaction
Enables full-duplex, low-latency conversations with a response time of 195 milliseconds.
Emotionally expressive
Preserves rich vocal nuances such as tone, rhythm, and emotion.
Persona-aware voice generation
Users can define speaker identity, tone, and characteristics via text instructions.
Pre-built voices
Supports over one million pre-built voices and customization from 10-second audio samples.
Unified model
Designed for ASR, TTS, and multilingual speech translation with minimal adaptation.
Whois
| Domain | voila.maitrix.org |
Featured Products
Scribewave
AudioNote
DupDub
Speechnotes
ScreenApp
Murf
Dubverse
Podcastle
Related Categories
Copy embed code
Alternative Products

Bocca

Omakase Voice AI

Helsa


earport.vercel.app-jSZrP2NcWM


Canopy Labs


agentsimulate.com-lJGDagub99

Lawonline